> ## Documentation Index
> Fetch the complete documentation index at: https://agentstack.cc/llms.txt
> Use this file to discover all available pages before exploring further.
# basic-knowledge
> basic knowledge about gpu and inference
## 一、初识模型推理:从训练到服务的“最后一公里”
当我们谈论大语言模型(LLM)时,通常会听到两个核心环节:**训练(Training)** 和 **推理(Inference)**。对于许多刚接触这个领域的同学来说,这两个概念可能有些模糊。让我们用一个生动的比喻来区分它们。
* **训练**,就像是让一个学生(模型)通过学习海量的书籍和资料(数据集),掌握知识和技能的过程。这个过程非常耗时耗力,需要大量的计算资源(成百上千张 GPU 卡)和时间(数周甚至数月),目标是“教会”模型,让它变得“聪明”。训练完成后,我们就得到了一个具备通用能力的、固化的模型文件。
* **推理**,则像是这位“学成归来”的学生,开始运用他所学的知识来回答具体问题、解决实际任务。每当用户发起一个请求(比如写一段代码、翻译一句话),模型都需要进行一次“思考”,并给出答案。这个过程,就是推理。它是模型知识应用的环节,是面向最终用户的服务形态。
简单来说,**训练是一次性的、为了“产出”模型;而推理是反复进行的、为了“使用”模型**。我们线上提供的大模型服务,其背后运行的正是推理过程。
### 大语言模型推理的核心两阶段:Prefill 与 Decode
与我们熟悉的很多传统AI模型不同,大语言模型的推理过程并非“一蹴而就”。由于其自回归(auto-regressive)的生成方式——即下一个词的生成依赖于之前所有内容——其推理过程被清晰地划分为两个核心阶段:**Prefill(预填充)** 和 **Decode(解码)**。
理解这两个阶段的差异,是理解 LLM 推理性能、瓶颈与优化的关键所在。
 #### 1. Prefill 阶段:并行处理,为“思考”做准备
**Prefill 阶段是模型接收用户输入(我们称之为 Prompt)并进行初始计算的过程。**
想象一下,当你向模型提问:“请帮我解释一下什么是‘光年’,并举一个例子。”
在这个阶段,模型会**一次性地、并行地**处理你输入的这整个句子中的每一个 Token(词或字)。它会为这个 Prompt 中的所有 Token 计算出所谓的 **Key-Value Cache(KV 缓存)**。这就像是模型在正式动笔回答前,先把你的问题完整阅读并深刻理解了一遍,将问题中的关键信息(上下文)提取并存储起来,为后续逐字生成答案做好准备。
**Prefill 阶段的核心特点:**
* **计算密集型(Compute-Bound)**:由于需要一次性处理整个较长的 Prompt,涉及大量的矩阵运算(Attention 计算),因此它非常消耗计算资源。只要 Prompt 足够长,GPU 的计算单元(如 Tensor Core)就能被充分利用起来,表现出很高的计算效率(SMA,Streaming Multiprocessor Active)。
* **高度并行**:对 Prompt 内的所有 Token 的处理是并行进行的,这是它与 Decode 阶段最本质的区别。
#### 2. Decode 阶段:逐字生成,如“挤牙膏”般的串行过程
**Decode 阶段紧随 Prefill 之后,是模型逐个生成回复内容的过程。**
在 Prefill 阶段准备好上下文(KV Cache)之后,模型便开始生成第一个 Token。然后,它会将这个新生成的 Token 作为输入,结合之前所有的 KV Cache,再生成第二个 Token……如此循环往复,直到生成完整的答案或遇到终止符(如 EOS, End-of-Sentence)。
这个过程就像我们写文章一样,是一个字一个字(或一个词一个词)向后写的,后面的内容依赖于前面的内容。
**Decode 阶段的核心特点:**
* **访存密集型(Memory-Bound)**:每生成一个 Token,虽然计算量不大(只处理一个 Token),但却需要从显存中读取完整的模型权重和之前累积的所有 KV Cache。数据搬运(从 HBM 显存到计算核心)的时间远大于实际计算的时间。因此,GPU 的计算单元大部分时间在“等待”数据,导致计算效率(SMA)通常不高。
* **严格串行**:每一步的计算都强依赖于上一步的输出,无法并行。生成 100 个 Token 就需要进行 100 次独立的、顺序的 forward(前向计算)过程。
**核心总结:Prefill 与 Decode 的关键差异**
* **处理对象**:Prefill 处理的是用户输入的 **Prompt**(多个 Token);Decode 处理的是模型自己 **生成的 Token**(一次一个)。
* **并行性**:Prefill 是 **高度并行** 的;Decode 是 **严格串行** 的。
* **性能瓶颈**:Prefill 倾向于 **计算密集 (Compute-Bound)**;Decode 倾向于 **访存密集 (Memory-Bound)**。
* **资源消耗**:Prefill 消耗大量的**计算资源**;Decode 消耗大量的**显存带宽**。
***
### 误区与澄清:深入理解 Prefill 与 Decode 的协作模式
对于 Prefill 和 Decode 的关系,初学者常常存在一些误解。澄清这些问题,有助于我们更准确地理解线上服务的真实运行机制。
#### 误区一:“Prefill 和 Decode 是严格轮流执行的,服务运行时要么在做 Prefill,要么在做 Decode。”
**澄清:** 这个描述**对单个请求来说是正确的,但对整个服务而言是错误的。**
* **从单个请求的视角看**:一个请求的生命周期的确是“先完成 Prefill,再进入 Decode”,两者不会交替。
* **从服务端的视角看**:一个现代的 LLM 推理服务(例如使用了 Continuous Batching 技术的服务)是**高度并行和异步**的。在任意时刻,GPU 上可能同时存在:
* 正在进行 Prefill 的**新请求**。
* 正在进行 Decode 的**大量存量请求**。
服务器的调度系统会非常智能地将这些不同阶段的请求“打包”在一起。例如,在一个迭代步中,GPU 可能先处理一批新请求的 Prefill,紧接着立即处理另一大批正在生成过程中的请求的 Decode。这种**交错执行、动态批处理**的方式,是最大化 GPU 利用率、提升服务吞un吐量的关键。
#### 误区二:“Decode 阶段一个请求基本就独占一张卡,所以 GPU 利用率很低。”
**澄清:** 这个说法具有很强的误导性,它**只在非常早期或简陋的推理框架中才成立。**
在早期的“朴素批处理(Naive Batching)”模式下,系统会等待多个请求凑成一个批次(batch),一起做完 Prefill,然后一起做 Decode。因为不同请求的生成长度不同,只要有一个请求没有生成完,整个批次的所有 GPU 资源都会被占用和等待,造成了“近似独占”和巨大的资源浪费。
然而,在目前主流的、采用**连续批处理(Continuous/In-flight Batching)** 技术的服务(如 vLLM, TGI)中,情况完全不同。系统会在 Decode 阶段的每一步,**聚合当前所有正在运行(in-flight)的请求,将它们需要生成的下一个 Token 组成一个微批次(micro-batch),共同完成一次前向计算**。
这意味着,在 Decode 阶段,GPU 并不是在为一个请求服务,而是同时为成百上千个请求各推进一步。**只要同时在途的请求数量(inflight request count)足够多,Decode 阶段的批次大小(batch size)就能变得很大,从而有效利用 GPU 的并行计算能力,提升 SMA。**
#### 误区三:“batch\_size 这个参数只对 Prefill 阶段有意义。”
**澄清:** 这个表述不完整。虽然我们通常讨论的、在请求入口处设置的 `batch_size` 主要影响 Prefill 阶段如何将请求打包,但 **Decode 阶段同样存在“批处理”**。
如上所述,Decode 阶段的“批处理”是一种动态形成的概念。它的大小不是由静态配置决定的,而是由当前 GPU 上正在并发处理的序列(Sequence)数量决定的。这个动态的批次,我们通常称之为 **“In-flight Batch”**。
因此,更准确的说法是:
* **Prefill Batch**:由调度器根据新到达的请求动态组成,旨在高效完成 Prompt 处理。
* **Decode Batch (In-flight Batch)**:由当前所有已完成 Prefill、正在逐个生成 Token 的请求在每一步动态聚合而成,旨在最大化 Decode 阶段的硬件利用率。
理解了这些,我们就为下一步深入探索 LLM 推理的性能优化技术打下了坚实的基础。
## 三、揭秘性能加速的“魔法”:让推理飞起来
LLM 推理,尤其是 Decode 阶段的访存瓶颈,决定了其性能优化的核心方向:**尽可能减少计算量,并最大化硬件利用率**。为此,业界发展出了一系列精妙的“魔法”,包括各种缓存机制、高效算子和先进的调度策略。
### 1. KV Cache:避免重复计算的基石
**KV Cache(Key-Value Cache)** 是 LLM 推理中最重要的优化之一,它的核心思想是:**缓存 Attention 计算中的 Key 和 Value,避免在生成每个新 Token 时重复计算历史信息。**
在 Transformer 架构中,一个 Token 的 Attention 计算需要依赖它之前所有 Token 的 Key 和 Value。在没有 KV Cache 的情况下,生成第 N 个 Token 就需要重新计算前 N-1 个 Token 的全部 Key 和 Value,计算量会随着生成长度的增加而急剧膨胀,这是完全无法接受的。
有了 KV Cache 后,流程变得高效得多:
1. **Prefill 阶段**:一次性计算出 Prompt 中所有 Token 的 Key 和 Value,并将它们存入 GPU 显存中的 KV Cache。
2. **Decode 阶段**:每生成一个新的 Token,只需要计算它自身的 Key 和 Value,然后将其追加到 KV Cache 的末尾。在进行 Attention 计算时,直接使用这个包含了所有历史信息的、不断增长的 KV Cache 即可。
这极大地减少了 Decode 阶段的计算量,使其从一个计算量随长度二次方增长的过程,变成了一个计算量基本固定的过程。
### 2. Prompt Cache & Page Cache:管理缓存的艺术
随着服务的复杂化,对 KV Cache 的管理也变得更加精细,衍生出了 Prompt Cache 和 Page Cache 等概念。这里需要特别澄清原文中的一些不准确之处。
* **Prompt Cache(或称 Prefix Caching)作用**:主要用于加速**拥有相同或相似前缀(Prefix)的多次请求**的 Prefill 过程。**存储内容**:它缓存的不是原文提到的“hidden states”,而是一个常见前缀经过 Prefill 计算后产生的 **KV Cache**。例如,在一个 RAG(检索增强生成)应用中,所有请求可能都共享一个长长的系统提示(System Prompt),比如:“你是一个乐于助人的 AI 助手,请根据以下知识库内容回答问题...”。通过 Prompt Cache,这个公共前缀的 KV Cache 只需计算一次并被所有后续请求复用。当一个新请求到来时,服务只需从这个缓存的 KV Cache 处继续计算其私有部分的 Prompt,从而显著减少 Prefill 的计算开销和延迟。
* **Page Cache(PagedAttention)作用**:这并非一个独立于 KV Cache 的缓存类型,而是 **一种先进的 KV Cache 管理技术**,其代表性实现是 vLLM 框架中的 **PagedAttention**。它的价值巨大,远非原文所说的“意义不大”。**核心解决的问题**:传统 KV Cache 管理方式会将一个请求的所有 KV 值存储在连续的显存块中。由于不同请求的长度千差万别,这会导致严重的**显存碎片化**问题。一个长请求结束后释放的显存空间,可能无法被一个短请求完全利用,造成大量“孔洞”,降低了显存的有效利用率,从而限制了服务的并发能力。
* **PagedAttention** 借鉴了操作系统中虚拟内存和分页的思想,它将 KV Cache 分割成固定大小的块(Page),这些块在物理显存中可以非连续存储。
- **PagedAttention 的巨大价值:**
- **消除内外部碎片**:通过页式管理,显存可以被灵活地分配和回收,几乎 100% 被有效利用。
- **实现高效的共享(Copy-on-Write)**:当多个请求共享同一个 Prompt 前缀时(例如,在 Beam Search 或多个并行的采样中),它们可以共享相同的物理 KV Cache 页面。只有当某个请求需要修改或追加内容时,才会为其复制一份新的页面。这极大地节省了显存。
* 因此,PagedAttention 是现代 LLM 服务框架能够实现高吞吐、高并发的关键技术之一,其意义至关重要。
### 3. Flash Attention:为 Attention 计算本身提速
**Flash Attention** 是一种经过极致优化的 Attention 算子(Kernel),它并不改变 Attention 的数学本质,而是通过更巧妙的计算顺序和对 GPU 硬件特性的充分利用,来解决传统 Attention 实现中的访存瓶颈。
**传统 Attention 实现的问题**:需要生成一个巨大的 N x N 的 Attention 矩阵(N 为序列长度),并将其完整地存放在 HBM(高带宽显存)中。当 N 很大时,这个矩阵会占用巨量显存,并且反复地读写它会带来高昂的带宽开销。
**Flash Attention 的优化**:
* **分块计算(Tiling)**:将输入数据切分成小块(Tile),每次只加载一小块到 SM(Streaming Multiprocessor)内部高速的 SRAM(共享内存)中进行计算。
* **融合算子(Kernel Fusion)**:将 Attention 计算的多个步骤(如矩阵乘、Softmax、加权求和)融合成一个单一的 GPU Kernel,避免了多次往返 HBM 读写中间结果。
* **重计算(Recomputation)**:在反向传播(训练时)中,通过重新计算部分中间结果来代替存储,进一步节省显存。
**传统 Attention**
* 产生 N×N 的中间矩阵
* 多次读写 HBM
* 显存占用大,带宽压力大
**Flash Attention**
* 无需存储完整中间矩阵
* 数据在 SRAM 内计算
* 显著减少显存占用和带宽压力
由于 Flash Attention 同时优化了计算和显存,它对 **Prefill 和 Decode 两个阶段都有效**。在 Prefill 阶段,它能处理更长的序列;在 Decode 阶段,它能加快每一步的 Attention 计算速度。
### 4. Continuous Batching:最大化 GPU 吞吐的调度核心
如前文所述,**连续批处理(Continuous Batching)** 或称 **In-flight Batching**,是现代 LLM 推理服务的核心调度策略。它摒弃了“等待所有请求完成”的低效模式,实现了对 GPU 资源的动态、高效利用。
**工作流程**:
1. 请求到达后,立即进入一个队列。
2. 调度器不断从队列中取出新请求,当 GPU 有空闲处理能力时,立即开始 Prefill。
3. 一个请求 Prefill 完成后,立刻进入“In-flight”状态,参与后续的 Decode 步骤。
4. 在每个 Decode 步骤,调度器会将在 flight 的所有请求聚合起来,形成一个动态的批次,送入 GPU 进行计算。
5. 任何一个请求生成完毕,其占用的资源会立即被释放,并可以被新的请求使用。
这种“即来即走、动态聚合”的模式,确保了 GPU 在任何时候都有活可干,从而极大地提升了 GPU 的利用率(SMA)和整个服务的吞吐量。
### 5. 其他加速技术:CUDA Graph 与 Tensor Parallelism
* **CUDA Graph**:通过记录一次前向计算中所有的 GPU Kernel 调用及其依赖关系,形成一个固定的“图”。在后续的执行中,只需一次提交这个图,就能让 GPU 自动执行所有操作,省去了 CPU 反复下发指令的开销(overhead)。这对于由大量小 Kernel 组成的 Decode 步骤尤其有效,能显著降低延迟。
* **Tensor Parallelism (TP, 张量并行)**:当单个模型大到一张 GPU 卡的显存无法容纳时,就需要使用张量并行技术。它将模型权重(特别是大的矩阵)切分到多张 GPU 卡上,每张卡只负责一部分计算。在 Prefill 和 Decode 阶段,多张卡需要通过高速互联(如 NVLink)协同工作,共同完成一次完整的前向计算。这是一种“用多卡服务一个请求”的模式,旨在解决单卡显存瓶颈。
## 四、更快的推理:探索性解码与模型量化
在前述优化的基础上,还有两种更激进的技术可以进一步压榨推理性能:Speculative Decoding 和模型量化。
### 1. Speculative Decoding:用“草稿模型”给主力模型减负
**Speculative Decoding(推测解码)** 是一种无损(输出结果与原模型完全一致)的加速技术。其核心思想是:**用一个计算开销极小的小模型(草稿模型, Draft Model),快速地生成一段候选文本(草稿),然后让能力强但计算昂贵的大模型(主模型, Target Model)一次性地、并行地验证这段草稿。**
**工作流程**:
1. **草稿生成**:在 Decode 的某一步,草稿模型(例如一个 1B 参数的小模型)一口气、自回归地生成 N 个 Token(比如 5个)。这个过程很快。
2. **并行验证**:主模型(例如一个 70B 的大模型)将这 N 个 Token 的草稿作为一个整体输入,进行一次 forward 计算,并行地验证这 N 个 Token 是否是它自己本来也会生成的。
3. **接受或拒绝**:
1. 如果主模型验证通过了前 k 个 Token,那么这 k 个 Token 就被直接接受为最终输出。我们一步就前进了 k 个 Token!
2. 如果在第 k+1 个 Token 处验证失败,主模型会拒绝草稿的剩余部分,并自己生成一个正确的 Token。然后流程从这个新生成的 Token 处重新开始。
**核心价值**:**大幅减少主模型参与 Decode 的次数**。主模型原本需要做 N 次 forward,现在理想情况下只需要做 1 次。这极大地节省了主模型的计算时间,相当于提升了主模型的吞吐能力。对于访存密集型的 Decode 阶段,这意味着主模型这张昂贵的卡可以被更快地释放出来,服务于其他请求。
### 2. 模型量化:压缩模型,挑战性能极限
**模型量化(Quantization)** 是一种通过降低模型参数(权重)和计算过程(激活)的数值精度,来减小模型体积、提升推理速度的技术。它是一种有损压缩,需要在性能和精度之间做出权衡。
#### 1. Prefill 阶段:并行处理,为“思考”做准备
**Prefill 阶段是模型接收用户输入(我们称之为 Prompt)并进行初始计算的过程。**
想象一下,当你向模型提问:“请帮我解释一下什么是‘光年’,并举一个例子。”
在这个阶段,模型会**一次性地、并行地**处理你输入的这整个句子中的每一个 Token(词或字)。它会为这个 Prompt 中的所有 Token 计算出所谓的 **Key-Value Cache(KV 缓存)**。这就像是模型在正式动笔回答前,先把你的问题完整阅读并深刻理解了一遍,将问题中的关键信息(上下文)提取并存储起来,为后续逐字生成答案做好准备。
**Prefill 阶段的核心特点:**
* **计算密集型(Compute-Bound)**:由于需要一次性处理整个较长的 Prompt,涉及大量的矩阵运算(Attention 计算),因此它非常消耗计算资源。只要 Prompt 足够长,GPU 的计算单元(如 Tensor Core)就能被充分利用起来,表现出很高的计算效率(SMA,Streaming Multiprocessor Active)。
* **高度并行**:对 Prompt 内的所有 Token 的处理是并行进行的,这是它与 Decode 阶段最本质的区别。
#### 2. Decode 阶段:逐字生成,如“挤牙膏”般的串行过程
**Decode 阶段紧随 Prefill 之后,是模型逐个生成回复内容的过程。**
在 Prefill 阶段准备好上下文(KV Cache)之后,模型便开始生成第一个 Token。然后,它会将这个新生成的 Token 作为输入,结合之前所有的 KV Cache,再生成第二个 Token……如此循环往复,直到生成完整的答案或遇到终止符(如 EOS, End-of-Sentence)。
这个过程就像我们写文章一样,是一个字一个字(或一个词一个词)向后写的,后面的内容依赖于前面的内容。
**Decode 阶段的核心特点:**
* **访存密集型(Memory-Bound)**:每生成一个 Token,虽然计算量不大(只处理一个 Token),但却需要从显存中读取完整的模型权重和之前累积的所有 KV Cache。数据搬运(从 HBM 显存到计算核心)的时间远大于实际计算的时间。因此,GPU 的计算单元大部分时间在“等待”数据,导致计算效率(SMA)通常不高。
* **严格串行**:每一步的计算都强依赖于上一步的输出,无法并行。生成 100 个 Token 就需要进行 100 次独立的、顺序的 forward(前向计算)过程。
**核心总结:Prefill 与 Decode 的关键差异**
* **处理对象**:Prefill 处理的是用户输入的 **Prompt**(多个 Token);Decode 处理的是模型自己 **生成的 Token**(一次一个)。
* **并行性**:Prefill 是 **高度并行** 的;Decode 是 **严格串行** 的。
* **性能瓶颈**:Prefill 倾向于 **计算密集 (Compute-Bound)**;Decode 倾向于 **访存密集 (Memory-Bound)**。
* **资源消耗**:Prefill 消耗大量的**计算资源**;Decode 消耗大量的**显存带宽**。
***
### 误区与澄清:深入理解 Prefill 与 Decode 的协作模式
对于 Prefill 和 Decode 的关系,初学者常常存在一些误解。澄清这些问题,有助于我们更准确地理解线上服务的真实运行机制。
#### 误区一:“Prefill 和 Decode 是严格轮流执行的,服务运行时要么在做 Prefill,要么在做 Decode。”
**澄清:** 这个描述**对单个请求来说是正确的,但对整个服务而言是错误的。**
* **从单个请求的视角看**:一个请求的生命周期的确是“先完成 Prefill,再进入 Decode”,两者不会交替。
* **从服务端的视角看**:一个现代的 LLM 推理服务(例如使用了 Continuous Batching 技术的服务)是**高度并行和异步**的。在任意时刻,GPU 上可能同时存在:
* 正在进行 Prefill 的**新请求**。
* 正在进行 Decode 的**大量存量请求**。
服务器的调度系统会非常智能地将这些不同阶段的请求“打包”在一起。例如,在一个迭代步中,GPU 可能先处理一批新请求的 Prefill,紧接着立即处理另一大批正在生成过程中的请求的 Decode。这种**交错执行、动态批处理**的方式,是最大化 GPU 利用率、提升服务吞un吐量的关键。
#### 误区二:“Decode 阶段一个请求基本就独占一张卡,所以 GPU 利用率很低。”
**澄清:** 这个说法具有很强的误导性,它**只在非常早期或简陋的推理框架中才成立。**
在早期的“朴素批处理(Naive Batching)”模式下,系统会等待多个请求凑成一个批次(batch),一起做完 Prefill,然后一起做 Decode。因为不同请求的生成长度不同,只要有一个请求没有生成完,整个批次的所有 GPU 资源都会被占用和等待,造成了“近似独占”和巨大的资源浪费。
然而,在目前主流的、采用**连续批处理(Continuous/In-flight Batching)** 技术的服务(如 vLLM, TGI)中,情况完全不同。系统会在 Decode 阶段的每一步,**聚合当前所有正在运行(in-flight)的请求,将它们需要生成的下一个 Token 组成一个微批次(micro-batch),共同完成一次前向计算**。
这意味着,在 Decode 阶段,GPU 并不是在为一个请求服务,而是同时为成百上千个请求各推进一步。**只要同时在途的请求数量(inflight request count)足够多,Decode 阶段的批次大小(batch size)就能变得很大,从而有效利用 GPU 的并行计算能力,提升 SMA。**
#### 误区三:“batch\_size 这个参数只对 Prefill 阶段有意义。”
**澄清:** 这个表述不完整。虽然我们通常讨论的、在请求入口处设置的 `batch_size` 主要影响 Prefill 阶段如何将请求打包,但 **Decode 阶段同样存在“批处理”**。
如上所述,Decode 阶段的“批处理”是一种动态形成的概念。它的大小不是由静态配置决定的,而是由当前 GPU 上正在并发处理的序列(Sequence)数量决定的。这个动态的批次,我们通常称之为 **“In-flight Batch”**。
因此,更准确的说法是:
* **Prefill Batch**:由调度器根据新到达的请求动态组成,旨在高效完成 Prompt 处理。
* **Decode Batch (In-flight Batch)**:由当前所有已完成 Prefill、正在逐个生成 Token 的请求在每一步动态聚合而成,旨在最大化 Decode 阶段的硬件利用率。
理解了这些,我们就为下一步深入探索 LLM 推理的性能优化技术打下了坚实的基础。
## 三、揭秘性能加速的“魔法”:让推理飞起来
LLM 推理,尤其是 Decode 阶段的访存瓶颈,决定了其性能优化的核心方向:**尽可能减少计算量,并最大化硬件利用率**。为此,业界发展出了一系列精妙的“魔法”,包括各种缓存机制、高效算子和先进的调度策略。
### 1. KV Cache:避免重复计算的基石
**KV Cache(Key-Value Cache)** 是 LLM 推理中最重要的优化之一,它的核心思想是:**缓存 Attention 计算中的 Key 和 Value,避免在生成每个新 Token 时重复计算历史信息。**
在 Transformer 架构中,一个 Token 的 Attention 计算需要依赖它之前所有 Token 的 Key 和 Value。在没有 KV Cache 的情况下,生成第 N 个 Token 就需要重新计算前 N-1 个 Token 的全部 Key 和 Value,计算量会随着生成长度的增加而急剧膨胀,这是完全无法接受的。
有了 KV Cache 后,流程变得高效得多:
1. **Prefill 阶段**:一次性计算出 Prompt 中所有 Token 的 Key 和 Value,并将它们存入 GPU 显存中的 KV Cache。
2. **Decode 阶段**:每生成一个新的 Token,只需要计算它自身的 Key 和 Value,然后将其追加到 KV Cache 的末尾。在进行 Attention 计算时,直接使用这个包含了所有历史信息的、不断增长的 KV Cache 即可。
这极大地减少了 Decode 阶段的计算量,使其从一个计算量随长度二次方增长的过程,变成了一个计算量基本固定的过程。
### 2. Prompt Cache & Page Cache:管理缓存的艺术
随着服务的复杂化,对 KV Cache 的管理也变得更加精细,衍生出了 Prompt Cache 和 Page Cache 等概念。这里需要特别澄清原文中的一些不准确之处。
* **Prompt Cache(或称 Prefix Caching)作用**:主要用于加速**拥有相同或相似前缀(Prefix)的多次请求**的 Prefill 过程。**存储内容**:它缓存的不是原文提到的“hidden states”,而是一个常见前缀经过 Prefill 计算后产生的 **KV Cache**。例如,在一个 RAG(检索增强生成)应用中,所有请求可能都共享一个长长的系统提示(System Prompt),比如:“你是一个乐于助人的 AI 助手,请根据以下知识库内容回答问题...”。通过 Prompt Cache,这个公共前缀的 KV Cache 只需计算一次并被所有后续请求复用。当一个新请求到来时,服务只需从这个缓存的 KV Cache 处继续计算其私有部分的 Prompt,从而显著减少 Prefill 的计算开销和延迟。
* **Page Cache(PagedAttention)作用**:这并非一个独立于 KV Cache 的缓存类型,而是 **一种先进的 KV Cache 管理技术**,其代表性实现是 vLLM 框架中的 **PagedAttention**。它的价值巨大,远非原文所说的“意义不大”。**核心解决的问题**:传统 KV Cache 管理方式会将一个请求的所有 KV 值存储在连续的显存块中。由于不同请求的长度千差万别,这会导致严重的**显存碎片化**问题。一个长请求结束后释放的显存空间,可能无法被一个短请求完全利用,造成大量“孔洞”,降低了显存的有效利用率,从而限制了服务的并发能力。
* **PagedAttention** 借鉴了操作系统中虚拟内存和分页的思想,它将 KV Cache 分割成固定大小的块(Page),这些块在物理显存中可以非连续存储。
- **PagedAttention 的巨大价值:**
- **消除内外部碎片**:通过页式管理,显存可以被灵活地分配和回收,几乎 100% 被有效利用。
- **实现高效的共享(Copy-on-Write)**:当多个请求共享同一个 Prompt 前缀时(例如,在 Beam Search 或多个并行的采样中),它们可以共享相同的物理 KV Cache 页面。只有当某个请求需要修改或追加内容时,才会为其复制一份新的页面。这极大地节省了显存。
* 因此,PagedAttention 是现代 LLM 服务框架能够实现高吞吐、高并发的关键技术之一,其意义至关重要。
### 3. Flash Attention:为 Attention 计算本身提速
**Flash Attention** 是一种经过极致优化的 Attention 算子(Kernel),它并不改变 Attention 的数学本质,而是通过更巧妙的计算顺序和对 GPU 硬件特性的充分利用,来解决传统 Attention 实现中的访存瓶颈。
**传统 Attention 实现的问题**:需要生成一个巨大的 N x N 的 Attention 矩阵(N 为序列长度),并将其完整地存放在 HBM(高带宽显存)中。当 N 很大时,这个矩阵会占用巨量显存,并且反复地读写它会带来高昂的带宽开销。
**Flash Attention 的优化**:
* **分块计算(Tiling)**:将输入数据切分成小块(Tile),每次只加载一小块到 SM(Streaming Multiprocessor)内部高速的 SRAM(共享内存)中进行计算。
* **融合算子(Kernel Fusion)**:将 Attention 计算的多个步骤(如矩阵乘、Softmax、加权求和)融合成一个单一的 GPU Kernel,避免了多次往返 HBM 读写中间结果。
* **重计算(Recomputation)**:在反向传播(训练时)中,通过重新计算部分中间结果来代替存储,进一步节省显存。
**传统 Attention**
* 产生 N×N 的中间矩阵
* 多次读写 HBM
* 显存占用大,带宽压力大
**Flash Attention**
* 无需存储完整中间矩阵
* 数据在 SRAM 内计算
* 显著减少显存占用和带宽压力
由于 Flash Attention 同时优化了计算和显存,它对 **Prefill 和 Decode 两个阶段都有效**。在 Prefill 阶段,它能处理更长的序列;在 Decode 阶段,它能加快每一步的 Attention 计算速度。
### 4. Continuous Batching:最大化 GPU 吞吐的调度核心
如前文所述,**连续批处理(Continuous Batching)** 或称 **In-flight Batching**,是现代 LLM 推理服务的核心调度策略。它摒弃了“等待所有请求完成”的低效模式,实现了对 GPU 资源的动态、高效利用。
**工作流程**:
1. 请求到达后,立即进入一个队列。
2. 调度器不断从队列中取出新请求,当 GPU 有空闲处理能力时,立即开始 Prefill。
3. 一个请求 Prefill 完成后,立刻进入“In-flight”状态,参与后续的 Decode 步骤。
4. 在每个 Decode 步骤,调度器会将在 flight 的所有请求聚合起来,形成一个动态的批次,送入 GPU 进行计算。
5. 任何一个请求生成完毕,其占用的资源会立即被释放,并可以被新的请求使用。
这种“即来即走、动态聚合”的模式,确保了 GPU 在任何时候都有活可干,从而极大地提升了 GPU 的利用率(SMA)和整个服务的吞吐量。
### 5. 其他加速技术:CUDA Graph 与 Tensor Parallelism
* **CUDA Graph**:通过记录一次前向计算中所有的 GPU Kernel 调用及其依赖关系,形成一个固定的“图”。在后续的执行中,只需一次提交这个图,就能让 GPU 自动执行所有操作,省去了 CPU 反复下发指令的开销(overhead)。这对于由大量小 Kernel 组成的 Decode 步骤尤其有效,能显著降低延迟。
* **Tensor Parallelism (TP, 张量并行)**:当单个模型大到一张 GPU 卡的显存无法容纳时,就需要使用张量并行技术。它将模型权重(特别是大的矩阵)切分到多张 GPU 卡上,每张卡只负责一部分计算。在 Prefill 和 Decode 阶段,多张卡需要通过高速互联(如 NVLink)协同工作,共同完成一次完整的前向计算。这是一种“用多卡服务一个请求”的模式,旨在解决单卡显存瓶颈。
## 四、更快的推理:探索性解码与模型量化
在前述优化的基础上,还有两种更激进的技术可以进一步压榨推理性能:Speculative Decoding 和模型量化。
### 1. Speculative Decoding:用“草稿模型”给主力模型减负
**Speculative Decoding(推测解码)** 是一种无损(输出结果与原模型完全一致)的加速技术。其核心思想是:**用一个计算开销极小的小模型(草稿模型, Draft Model),快速地生成一段候选文本(草稿),然后让能力强但计算昂贵的大模型(主模型, Target Model)一次性地、并行地验证这段草稿。**
**工作流程**:
1. **草稿生成**:在 Decode 的某一步,草稿模型(例如一个 1B 参数的小模型)一口气、自回归地生成 N 个 Token(比如 5个)。这个过程很快。
2. **并行验证**:主模型(例如一个 70B 的大模型)将这 N 个 Token 的草稿作为一个整体输入,进行一次 forward 计算,并行地验证这 N 个 Token 是否是它自己本来也会生成的。
3. **接受或拒绝**:
1. 如果主模型验证通过了前 k 个 Token,那么这 k 个 Token 就被直接接受为最终输出。我们一步就前进了 k 个 Token!
2. 如果在第 k+1 个 Token 处验证失败,主模型会拒绝草稿的剩余部分,并自己生成一个正确的 Token。然后流程从这个新生成的 Token 处重新开始。
**核心价值**:**大幅减少主模型参与 Decode 的次数**。主模型原本需要做 N 次 forward,现在理想情况下只需要做 1 次。这极大地节省了主模型的计算时间,相当于提升了主模型的吞吐能力。对于访存密集型的 Decode 阶段,这意味着主模型这张昂贵的卡可以被更快地释放出来,服务于其他请求。
### 2. 模型量化:压缩模型,挑战性能极限
**模型量化(Quantization)** 是一种通过降低模型参数(权重)和计算过程(激活)的数值精度,来减小模型体积、提升推理速度的技术。它是一种有损压缩,需要在性能和精度之间做出权衡。
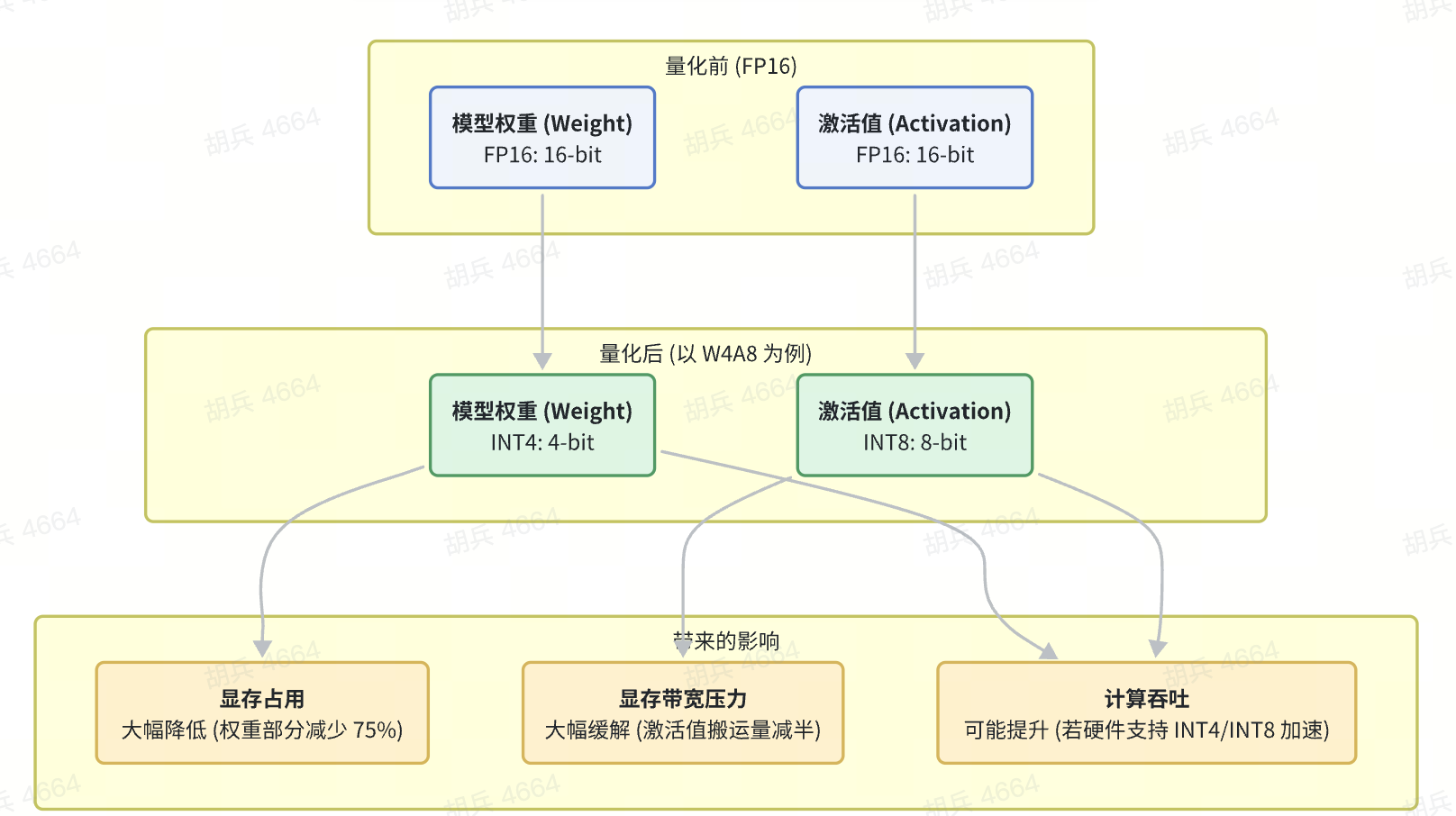 #### 什么是 W4A8?权重量化与激活量化
我们常听到的 **W4A8** 就是一种量化方案的缩写:
* **W4 (Weights 4-bit)**:将模型的**权重(Weights)** 从常规的 16-bit 浮点数(FP16)压缩到 4-bit 整数(INT4)。
* **A8 (Activations 8-bit)**:将在推理过程中动态产生的**激活值(Activations)** 从 FP16 压缩到 8-bit 整数(INT8)。
**权重量化(Weight Quantization)**:
* **对象**:模型训练好后固定不变的参数。它们数量巨大,常驻显存。
* **好处**:
* **显著降低显存占用**:一个 7B 的 FP16 模型约占 14GB 显存,量化到 INT4 后仅需约 3.5GB。这使得在更小的 GPU 上运行大模型成为可能。
* **可能提升计算吞吐**:如果 GPU 硬件(如 NVIDIA 的新一代 Tensor Core)对 INT4/INT8 计算有原生加速,那么单次计算可以处理更多数据,提升效率。
**激活量化(Activation Quantization)**:
* **对象**:模型在推理时,每一层网络计算产生的中间结果。它们是动态变化的,生命周期短,但数量庞大,需要在 GPU 的存储层级中频繁搬运。
* **好处**:
* **大幅降低显存带宽压力**:这是激活量化最核心的价值。在访存密集的 Decode 阶段,将激活值从 16-bit 减半到 8-bit,意味着从 HBM 到计算核心的整条数据通路的搬运量减半。**激活量化是解决 Memory-Bound 问题的关键武器。**
#### PTQ vs QAT:如何进行量化?
* **PTQ (Post-Training Quantization)**:训练后量化。这是一种简单快捷的方式,直接对已经训练好的 FP16 模型进行量化转换。它不需要重新训练,成本低,是目前 LLM 推理应用最广泛的方案。
* **QAT (Quantization-Aware Training)**:量化感知训练。在训练过程中就“模拟”量化的效应,让模型去适应低精度带来的误差。这种方法通常能获得比 PTQ 更高的精度,但需要额外的训练成本。
#### FP8:一种新的可能性
除了 INT8/INT4,**FP8(8-bit 浮点数)** 也是一种新兴的、极具潜力的量化格式。相比整数,它保留了浮点数的动态范围优势,对异常值(outliers)更不敏感,因此在很多场景下能以更小的精度损失换取与 INT8 相当的性能收益。NVIDIA Hopper 和 Blackwell 架构的 GPU 已经对 FP8 提供了强大的硬件支持。
## 五、深入 GPU 硬件:理解算力与带宽的“物理规则”
为了真正理解性能瓶颈,我们需要从软件层深入到硬件层,看看 GPU 是如何工作的。对于初学者而言,无需了解所有电路细节,但建立一个关于其核心组件和数据流的直观认知至关重要。
### 1. GPU 架构概览:计算工厂与多级仓库
我们可以将一张 GPU 想象成一个由\*\*“计算工厂”**和**“多级仓储系统”\*\*组成的庞大体系。
* **计算工厂**:指的是真正执行数学运算的单元,即 **Streaming Multiprocessors (SMs)** 及其内部的 **CUDA Cores** 和 **Tensor Cores**。它们负责消耗 FLOPs(浮点运算次数),是算力的源泉。
* **多级仓储系统**:指的是 GPU 内部层级分明、速度和容量各异的存储单元。数据(模型权重、激活值)必须在这些仓库之间高效流转,才能喂饱计算工厂。
#### 什么是 W4A8?权重量化与激活量化
我们常听到的 **W4A8** 就是一种量化方案的缩写:
* **W4 (Weights 4-bit)**:将模型的**权重(Weights)** 从常规的 16-bit 浮点数(FP16)压缩到 4-bit 整数(INT4)。
* **A8 (Activations 8-bit)**:将在推理过程中动态产生的**激活值(Activations)** 从 FP16 压缩到 8-bit 整数(INT8)。
**权重量化(Weight Quantization)**:
* **对象**:模型训练好后固定不变的参数。它们数量巨大,常驻显存。
* **好处**:
* **显著降低显存占用**:一个 7B 的 FP16 模型约占 14GB 显存,量化到 INT4 后仅需约 3.5GB。这使得在更小的 GPU 上运行大模型成为可能。
* **可能提升计算吞吐**:如果 GPU 硬件(如 NVIDIA 的新一代 Tensor Core)对 INT4/INT8 计算有原生加速,那么单次计算可以处理更多数据,提升效率。
**激活量化(Activation Quantization)**:
* **对象**:模型在推理时,每一层网络计算产生的中间结果。它们是动态变化的,生命周期短,但数量庞大,需要在 GPU 的存储层级中频繁搬运。
* **好处**:
* **大幅降低显存带宽压力**:这是激活量化最核心的价值。在访存密集的 Decode 阶段,将激活值从 16-bit 减半到 8-bit,意味着从 HBM 到计算核心的整条数据通路的搬运量减半。**激活量化是解决 Memory-Bound 问题的关键武器。**
#### PTQ vs QAT:如何进行量化?
* **PTQ (Post-Training Quantization)**:训练后量化。这是一种简单快捷的方式,直接对已经训练好的 FP16 模型进行量化转换。它不需要重新训练,成本低,是目前 LLM 推理应用最广泛的方案。
* **QAT (Quantization-Aware Training)**:量化感知训练。在训练过程中就“模拟”量化的效应,让模型去适应低精度带来的误差。这种方法通常能获得比 PTQ 更高的精度,但需要额外的训练成本。
#### FP8:一种新的可能性
除了 INT8/INT4,**FP8(8-bit 浮点数)** 也是一种新兴的、极具潜力的量化格式。相比整数,它保留了浮点数的动态范围优势,对异常值(outliers)更不敏感,因此在很多场景下能以更小的精度损失换取与 INT8 相当的性能收益。NVIDIA Hopper 和 Blackwell 架构的 GPU 已经对 FP8 提供了强大的硬件支持。
## 五、深入 GPU 硬件:理解算力与带宽的“物理规则”
为了真正理解性能瓶颈,我们需要从软件层深入到硬件层,看看 GPU 是如何工作的。对于初学者而言,无需了解所有电路细节,但建立一个关于其核心组件和数据流的直观认知至关重要。
### 1. GPU 架构概览:计算工厂与多级仓库
我们可以将一张 GPU 想象成一个由\*\*“计算工厂”**和**“多级仓储系统”\*\*组成的庞大体系。
* **计算工厂**:指的是真正执行数学运算的单元,即 **Streaming Multiprocessors (SMs)** 及其内部的 **CUDA Cores** 和 **Tensor Cores**。它们负责消耗 FLOPs(浮点运算次数),是算力的源泉。
* **多级仓储系统**:指的是 GPU 内部层级分明、速度和容量各异的存储单元。数据(模型权重、激活值)必须在这些仓库之间高效流转,才能喂饱计算工厂。
 这个仓储系统遵循一个基本原则:**离计算核心越近,速度越快,但容量越小。**
1. **HBM (High Bandwidth Memory, 高带宽显存)**:
1. **定位**:最大但最慢的“远郊大仓库”。它位于 GPU 芯片(Die)的外部,通过高密度接口连接。
2. **特点**:容量巨大(几十 GB),是唯一能容纳下整个大模型权重和 KV Cache 的地方。带宽极高(可达 TB/s 级别),但相比片上存储,其访问延迟仍然是最高的。
2. **L2 Cache (二级缓存)**:
1. **定位**:连接所有 SM 的“市中心中转站”。它位于 GPU 芯片内部,为所有 SM 共享。
2. **特点**:容量中等(几十 MB),速度远快于 HBM。它试图缓存从 HBM 中读取的热点数据,以减少对 HBM 的直接访问。
3. **Shared Memory & Registers (共享内存与寄存器)**:
1. **定位**:SM 内部的“车间暂存区”和“工位工具台”,是最高速的存储。
2. **Shared Memory**:由一个 SM 内的所有线程块(Thread Block)共享,容量约几十到上百 KB。常用于存放需要被多个线程重复访问的数据块(Tile)。
3. **Registers**:每个线程私有的“口袋”,速度最快,容量极小。计算单元(Tensor Core)直接从这里取用数据进行计算。
**补全与澄清:SM 与 Register 的关系**
原文中提到 `SM 和 Register 是什么关系? TBD`。
准确的关系是:**SM (Streaming Multiprocessor) 是一个完整的计算单元,而 Register (寄存器) 是 SM 内部、每个计算线程 (Thread) 私有的、最快的一级存储空间。**
一个 SM 包含了很多组件:大量的 CUDA Cores / Tensor Cores(用于计算),调度器(分发任务),以及存储层次中的 L1 Cache、Shared Memory 和大量的 Registers。当一个计算任务被分配给一个 SM 时,它会被分解成许多线程。每个线程都会被分配一套独立的寄存器,用来存放它当前正在处理的变量和中间结果。Tensor Core 进行计算时,其操作数(Operands)就直接来自于这些寄存ator。
所以,它们是**包含与被包含**的关系:**GPU 包含多个 SM,每个 SM 包含多个处理核心和一套存储体系,而寄存器是这套体系中最贴近计算核心的部分。**
### 2. 一次矩阵乘法的数据之旅
让我们以一次典型的矩阵乘法(`output = activation × weight`)为例,追踪数据在 GPU 内部的完整“搬运链路”:
1. **Step 1: 数据源于 HBM**模型巨大的权重矩阵和中间结果激活值向量,都静静地躺在 HBM 显存中。
2. **Step 2: HBM → L2 Cache**计算开始,GPU 的内存控制器发出指令,将即将用到的权重和激活值从 HBM 加载到 L2 缓存。
3. **Step 3: L2 Cache → SM Shared Memory**数据被进一步分块(Tiling),每个 SM 只负责计算结果矩阵的一小部分。相应的数据块被加载到对应 SM 的共享内存中,准备给众多线程共享。
4. **Step 4: Shared Memory → Registers**SM 内的每个线程从共享内存中领取自己负责计算的几行或几列数据,放入自己私有的寄存器中。这是数据到达计算核心前的最后一站。
5. \*\*Step 5: 计算发生!\*\*Tensor Core 从寄存器中取出数据,执行真正的矩阵乘加运算(GEMM, FMA),消耗算力(FLOPs)。
6. **Step 6: 结果写回**计算出的结果沿着原路返回:Register → Shared Memory → L2 Cache → HBM,最终存回显存,等待下一轮计算使用。
### 3. Memory-Bound vs. Compute-Bound:你的瓶颈在哪里?
理解了数据链路后,我们就能清晰地定义两种核心的性能瓶颈:
* **Compute-Bound (计算受限)**
* **特征**:计算单元(Tensor Cores)一直很忙,满负荷运转,而数据供应非常及时。
* **表现**:GPU 利用率(SMA)很高,性能主要取决于 GPU 的理论峰值算力(TFLOPs)。
* **常见场景**:**Prefill 阶段**(处理长 Prompt)、模型训练。在这些场景下,有大量的并行计算任务,可以有效隐藏数据访问延迟。
* **Memory-Bound (访存/带宽受限)**
* **特征**:计算单元大部分时间在“等待”数据从 HBM 搬运过来,算得快,等得久。
* **表现**:GPU 利用率(SMA)很低,性能主要取决于 GPU 的显存带宽。
* **常见场景**:**Decode 阶段**。每生成一个 Token,计算量很小(一个“瘦”矩阵乘法),但需要访问的数据量却很大(整个模型权重 + 增长的 KV Cache)。**数据搬运时间远大于计算时间**,导致瓶颈出现在“搬运”这个环节。
**如何优化?**
* **对抗 Compute-Bound**:
* 使用更强的 GPU(更高的 TFLOPs)。
* 使用更高效的并行策略(如 Tensor Parallelism)。
* **对抗 Memory-Bound**:
* **激活量化 (A8)**:直接减少数据搬运量,是“特效药”。
* **Flash Attention**:减少对 HBM 的读写次数。
* **融合算子 (Kernel Fusion)**:将多个小 Kernel 合并成一个,减少调度和启动开销。
* 提升批处理大小(Batch Size),让单次计算处理更多数据,摊薄访存开销。
## 六、线上服务的挑战与权衡
将模型部署到线上,我们面对的不再是单一的性能指标,而是一个复杂的系统工程,需要在成本、延迟和用户体验之间做出精妙的平衡。
### 1. 核心衡量指标:不止是快
* **吞吐量 (Throughput)**:衡量系统在单位时间内能处理多少请求或生成多少 Token。这是衡量系统“容量”和效率的核心指标,通常以 `requests/sec` 或 `output tokens/sec` 计。
* **延迟 (Latency)**:
* **Time to First Token (TTFT, 首 Token 延迟)**:从用户发送请求到收到第一个生成 Token 的时间。它主要由 **Prefill 阶段**的耗时决定,直接影响用户的“初始响应感”。
* **Time Per Output Token (TPOT, 每 Token 延迟)**:生成每个后续 Token 的平均时间。它由 **Decode 阶段**的耗时决定,影响用户感知到的“生成速度”。
* **尾延迟 (Tail Latency)**:例如 P99 延迟,指 99% 的请求都能在此时间内完成。高尾延迟意味着部分用户会经历“卡顿”,是衡量服务稳定性的重要指标。
* **GPU 利用率 (SMA)**:衡量 GPU 计算核心的繁忙程度。高 SMA 意味着硬件资源被充分利用,成本效益高。
这些指标往往是相互制约的。例如,为了降低延迟,我们可能会使用小批次(small batch),但这会导致 SMA 下降,吞吐量降低。反之,为了最大化吞吐量而采用大批次(large batch),则可能增加每个请求的排队时间,从而推高延迟。
### 2. 线上资源编排与策略
* **多实例与水平扩展 (HPA)**:
* 在一台多卡服务器上,可以通过 **MIG (Multi-Instance GPU)** 技术将一张物理 GPU 切分成多个隔离的“小 GPU”,每个实例独立提供服务。这适用于小模型或低负载场景,可以提升资源利用率。
* 更常见的是为模型服务配置 **HPA (Horizontal Pod Autoscaler)**。通过监控 CPU/GPU 负载或 QPS 等指标,自动增减服务实例(Pod)的数量。在夜间低峰期,应将最小实例数降到足够低,避免资源空跑和成本浪费。
* **分离 Prefill 和 Decode 集群**:鉴于 Prefill 和 Decode 的资源需求差异巨大,一些先进的架构会考虑将其部署在不同的物理集群上。
* **Prefill 集群**:可以使用计算能力强、但显存或带宽可以稍低的卡,专门处理计算密集的 Prompt。
* **Decode 集群**:可以使用显存带宽极高、或针对低延迟优化的卡,专门处理访存密集、小批量的生成任务。这种分离部署需要解决 KV Cache 在集群间的快速传输问题,但能实现更极致的资源匹配和成本优化。
* **负载均衡与调度**:确保请求能被均匀地分发到所有可用的 GPU 实例上,避免“忙的忙死,闲的闲死”。对于有状态的推理服务(需要维护 KV Cache),需要采用更智能的、考虑会话亲和性(Session Affinity)的负载均衡策略。
最终,一个优秀的 LLM 推理服务,是在深刻理解模型、硬件和业务需求的基础上,通过精巧的架构设计、细致的性能优化和智能的资源调度,达成的一个动态平衡。
这个仓储系统遵循一个基本原则:**离计算核心越近,速度越快,但容量越小。**
1. **HBM (High Bandwidth Memory, 高带宽显存)**:
1. **定位**:最大但最慢的“远郊大仓库”。它位于 GPU 芯片(Die)的外部,通过高密度接口连接。
2. **特点**:容量巨大(几十 GB),是唯一能容纳下整个大模型权重和 KV Cache 的地方。带宽极高(可达 TB/s 级别),但相比片上存储,其访问延迟仍然是最高的。
2. **L2 Cache (二级缓存)**:
1. **定位**:连接所有 SM 的“市中心中转站”。它位于 GPU 芯片内部,为所有 SM 共享。
2. **特点**:容量中等(几十 MB),速度远快于 HBM。它试图缓存从 HBM 中读取的热点数据,以减少对 HBM 的直接访问。
3. **Shared Memory & Registers (共享内存与寄存器)**:
1. **定位**:SM 内部的“车间暂存区”和“工位工具台”,是最高速的存储。
2. **Shared Memory**:由一个 SM 内的所有线程块(Thread Block)共享,容量约几十到上百 KB。常用于存放需要被多个线程重复访问的数据块(Tile)。
3. **Registers**:每个线程私有的“口袋”,速度最快,容量极小。计算单元(Tensor Core)直接从这里取用数据进行计算。
**补全与澄清:SM 与 Register 的关系**
原文中提到 `SM 和 Register 是什么关系? TBD`。
准确的关系是:**SM (Streaming Multiprocessor) 是一个完整的计算单元,而 Register (寄存器) 是 SM 内部、每个计算线程 (Thread) 私有的、最快的一级存储空间。**
一个 SM 包含了很多组件:大量的 CUDA Cores / Tensor Cores(用于计算),调度器(分发任务),以及存储层次中的 L1 Cache、Shared Memory 和大量的 Registers。当一个计算任务被分配给一个 SM 时,它会被分解成许多线程。每个线程都会被分配一套独立的寄存器,用来存放它当前正在处理的变量和中间结果。Tensor Core 进行计算时,其操作数(Operands)就直接来自于这些寄存ator。
所以,它们是**包含与被包含**的关系:**GPU 包含多个 SM,每个 SM 包含多个处理核心和一套存储体系,而寄存器是这套体系中最贴近计算核心的部分。**
### 2. 一次矩阵乘法的数据之旅
让我们以一次典型的矩阵乘法(`output = activation × weight`)为例,追踪数据在 GPU 内部的完整“搬运链路”:
1. **Step 1: 数据源于 HBM**模型巨大的权重矩阵和中间结果激活值向量,都静静地躺在 HBM 显存中。
2. **Step 2: HBM → L2 Cache**计算开始,GPU 的内存控制器发出指令,将即将用到的权重和激活值从 HBM 加载到 L2 缓存。
3. **Step 3: L2 Cache → SM Shared Memory**数据被进一步分块(Tiling),每个 SM 只负责计算结果矩阵的一小部分。相应的数据块被加载到对应 SM 的共享内存中,准备给众多线程共享。
4. **Step 4: Shared Memory → Registers**SM 内的每个线程从共享内存中领取自己负责计算的几行或几列数据,放入自己私有的寄存器中。这是数据到达计算核心前的最后一站。
5. \*\*Step 5: 计算发生!\*\*Tensor Core 从寄存器中取出数据,执行真正的矩阵乘加运算(GEMM, FMA),消耗算力(FLOPs)。
6. **Step 6: 结果写回**计算出的结果沿着原路返回:Register → Shared Memory → L2 Cache → HBM,最终存回显存,等待下一轮计算使用。
### 3. Memory-Bound vs. Compute-Bound:你的瓶颈在哪里?
理解了数据链路后,我们就能清晰地定义两种核心的性能瓶颈:
* **Compute-Bound (计算受限)**
* **特征**:计算单元(Tensor Cores)一直很忙,满负荷运转,而数据供应非常及时。
* **表现**:GPU 利用率(SMA)很高,性能主要取决于 GPU 的理论峰值算力(TFLOPs)。
* **常见场景**:**Prefill 阶段**(处理长 Prompt)、模型训练。在这些场景下,有大量的并行计算任务,可以有效隐藏数据访问延迟。
* **Memory-Bound (访存/带宽受限)**
* **特征**:计算单元大部分时间在“等待”数据从 HBM 搬运过来,算得快,等得久。
* **表现**:GPU 利用率(SMA)很低,性能主要取决于 GPU 的显存带宽。
* **常见场景**:**Decode 阶段**。每生成一个 Token,计算量很小(一个“瘦”矩阵乘法),但需要访问的数据量却很大(整个模型权重 + 增长的 KV Cache)。**数据搬运时间远大于计算时间**,导致瓶颈出现在“搬运”这个环节。
**如何优化?**
* **对抗 Compute-Bound**:
* 使用更强的 GPU(更高的 TFLOPs)。
* 使用更高效的并行策略(如 Tensor Parallelism)。
* **对抗 Memory-Bound**:
* **激活量化 (A8)**:直接减少数据搬运量,是“特效药”。
* **Flash Attention**:减少对 HBM 的读写次数。
* **融合算子 (Kernel Fusion)**:将多个小 Kernel 合并成一个,减少调度和启动开销。
* 提升批处理大小(Batch Size),让单次计算处理更多数据,摊薄访存开销。
## 六、线上服务的挑战与权衡
将模型部署到线上,我们面对的不再是单一的性能指标,而是一个复杂的系统工程,需要在成本、延迟和用户体验之间做出精妙的平衡。
### 1. 核心衡量指标:不止是快
* **吞吐量 (Throughput)**:衡量系统在单位时间内能处理多少请求或生成多少 Token。这是衡量系统“容量”和效率的核心指标,通常以 `requests/sec` 或 `output tokens/sec` 计。
* **延迟 (Latency)**:
* **Time to First Token (TTFT, 首 Token 延迟)**:从用户发送请求到收到第一个生成 Token 的时间。它主要由 **Prefill 阶段**的耗时决定,直接影响用户的“初始响应感”。
* **Time Per Output Token (TPOT, 每 Token 延迟)**:生成每个后续 Token 的平均时间。它由 **Decode 阶段**的耗时决定,影响用户感知到的“生成速度”。
* **尾延迟 (Tail Latency)**:例如 P99 延迟,指 99% 的请求都能在此时间内完成。高尾延迟意味着部分用户会经历“卡顿”,是衡量服务稳定性的重要指标。
* **GPU 利用率 (SMA)**:衡量 GPU 计算核心的繁忙程度。高 SMA 意味着硬件资源被充分利用,成本效益高。
这些指标往往是相互制约的。例如,为了降低延迟,我们可能会使用小批次(small batch),但这会导致 SMA 下降,吞吐量降低。反之,为了最大化吞吐量而采用大批次(large batch),则可能增加每个请求的排队时间,从而推高延迟。
### 2. 线上资源编排与策略
* **多实例与水平扩展 (HPA)**:
* 在一台多卡服务器上,可以通过 **MIG (Multi-Instance GPU)** 技术将一张物理 GPU 切分成多个隔离的“小 GPU”,每个实例独立提供服务。这适用于小模型或低负载场景,可以提升资源利用率。
* 更常见的是为模型服务配置 **HPA (Horizontal Pod Autoscaler)**。通过监控 CPU/GPU 负载或 QPS 等指标,自动增减服务实例(Pod)的数量。在夜间低峰期,应将最小实例数降到足够低,避免资源空跑和成本浪费。
* **分离 Prefill 和 Decode 集群**:鉴于 Prefill 和 Decode 的资源需求差异巨大,一些先进的架构会考虑将其部署在不同的物理集群上。
* **Prefill 集群**:可以使用计算能力强、但显存或带宽可以稍低的卡,专门处理计算密集的 Prompt。
* **Decode 集群**:可以使用显存带宽极高、或针对低延迟优化的卡,专门处理访存密集、小批量的生成任务。这种分离部署需要解决 KV Cache 在集群间的快速传输问题,但能实现更极致的资源匹配和成本优化。
* **负载均衡与调度**:确保请求能被均匀地分发到所有可用的 GPU 实例上,避免“忙的忙死,闲的闲死”。对于有状态的推理服务(需要维护 KV Cache),需要采用更智能的、考虑会话亲和性(Session Affinity)的负载均衡策略。
最终,一个优秀的 LLM 推理服务,是在深刻理解模型、硬件和业务需求的基础上,通过精巧的架构设计、细致的性能优化和智能的资源调度,达成的一个动态平衡。