概念整理
- W8A8 是“全模型量化策略”;FP8 Attention 是“只针对 Attention 的高价值 kernel 优化”
- **w8A8 作用范围: **Attention 里的 QKV / O; MLP 的 FC1 / FC2
- FP8 Attention: 只把 **Attention 里的关键算子 **QK^T、Softmax 前后、V projection 换成 FP8(E4M3 / E5M2)
- KV Cache 写入的数据通常以 FP16/BF16 存储(为了稳定性),即使前向计算用了 int8,写回还是可能升回 FP16。
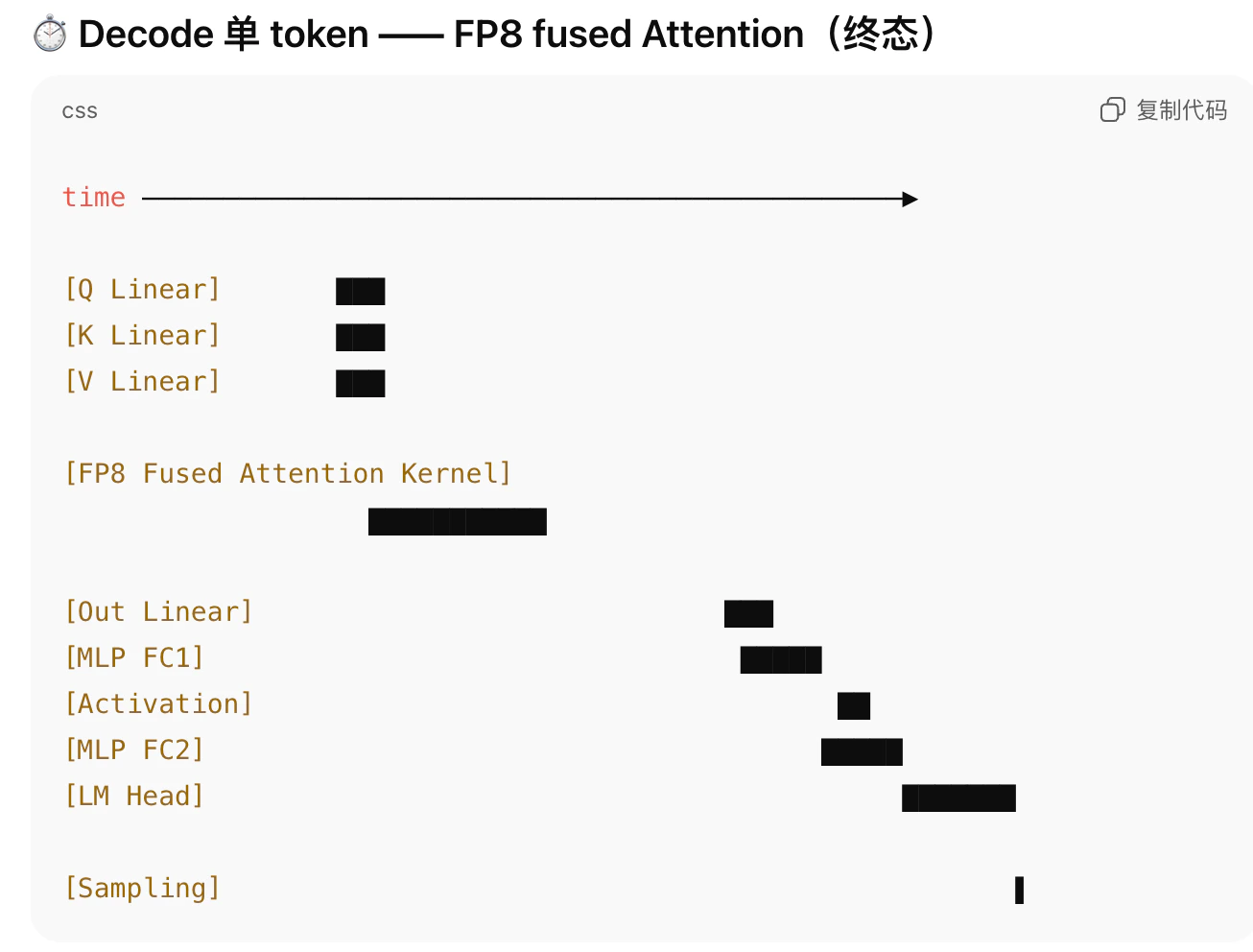
- FP8 Attention 主要作用在 Decode 阶段的 Q×Kᵀ 和 A×V 这两个 attention 核心算子上,通过更低的 kernel 启动成本 + fused 执行 + 合适的数值表示,减少 HBM stall,从而提升 SMA
- FP8 Attention = Attention 的某些“中间计算表示”使用 FP8,而不是 FP16;FP8 Attention 是 **“算的时候用 FP8,存的时候不用 FP8”;**FP8 Attention 并不是简单把 Attention 的所有数据从 FP16 换成 FP8,而是把 Attention 内部的高频中间计算(尤其是 QK 和 AV)用 FP8 表示,并在一个 fused kernel 内完成计算
- Attention: 用当前 token 作为查询(Query),去“匹配”历史所有 token(Keys),再把匹配结果当权重,对历史信息(Values)做加权求和
- Attention 把 Query:「你是谁」聚合; MLP 学到的是:“这是一个自我介绍问题”,“应该用第一人称回答”
- rollout:给「训练系统」采样数据;RL 里面会 rollout 多个回答
prefill过程阶段
- Linear 投影(Q ,K,V) : gemm
- reshape/transposes(把 Q/K/V 拆成 heads)
- 计算相似度矩阵 S = Q × Kᵀ(未归一化): 「相关性打分」;“当前 token 和第 i 个历史 token 有多相关?;S 大 → 更关注,S 小 → 忽略;访问 整个 K Cache;q / k 用 FP8;QKᵀ 用 FP8 Tensor Core
- Softmax:S -> A(注意力权重矩阵), A = softmax(S); 把“相关性分数”变成“概率权重”
- 注意力上下文 O = A × V;A:每个历史 token 的“重要程度”,V:每个历史 token 的“内容”,所以:用重要程度当权重,对内容做加权平均;访问整个 V Cache; A / V 用 FP8 or FP16;FP8 Tensor Core;fused kernel 内完成
- 输出线性投影(Out-Projection) + residual
decode过程阶段
- Linear 投影 Q/K/V
- reshape/transposes
- S = Q × Kᵀ
- 这里要加载整个历史 K_cache(长度 L),这一步对 HBM 带宽极度敏感:每 step 都要大量读取 K(和后续对 V 的读取)。这使得 decode 极度 memory-bound(HBM 带宽 dominate),尤其当 L 很长时
- 这里 Q 以及 Q × Kᵀ 使用 FP8 精度
- Softmax -> A
- O = A × V 5. 计算的时候使用 FP8
- Out projection + write new K/V : 输出后要对当前 token 计算新的 K/V 并 append 到 KV cache(写入 HBM)
什么是 forward

什么是 backward
-
- Backward(反向传播)= “算梯度、更新权重”
- 只要“参数要被更新”,就一定有 backward
- 是从一个 loss 出发:告诉模型:“刚才你哪算错了,权重该怎么改”
- SFT和 RL 都包含 backward